Data management has always been a tricky business in the Earth Observation (EO) world, with the storage, access and searching of multiple terabytes of satellite imagery being often incredibly expensive and time consuming. The STAC (SpatioTemporal Asset Catalog) specification is one of the most important and exciting recent developments in the geospatial industry. This might sound like a bit of an exaggeration if you’re not usually excited by metadata standards, but STAC really does have the potential to make many aspects of working with EO data far, far easier & cost effective. In this article we’ll explore the basics of STAC, how it works, and why you should be using it.
STAC is a very young spec – v1 was only finalised in 2021, but the ecosystem of tools is rapidly expanding and it gives us the opportunity to free us up for the more interesting things rather than boring & expensive data management.
From the site, STAC is described as “a common language to describe geospatial information, so it can more easily be worked with, indexed, and discovered”. The ‘indexing and discover’ piece is the key to what makes STAC so powerful. For decades now, the geospatial community has benefited from open standards that allow data to be easily consumed (e.g. API and file formats from the Open Geospatial Consortium (OGC) ) but even as the availability of open data has skyrocketed, organisations are having to re-invent the wheel every time, or rely on complex, monolithic data management solutions when it comes to cataloging and metadata.
STAC provides a common language for data providers, developers and data users to interface with, but also allows the development of common reusable tooling that can drastically reduce the effort and cost required for common geospatial workflows.
STAC’s openness and flexibility enables a ‘build what you need’, plug and play approach with systems and tooling. This is enabled by the way the standard is constructed, and its reliance on cloud native approaches.
The specification itself is actually four discrete “semi-independent” specifications which can be built on top of each other to enable more capabilities.
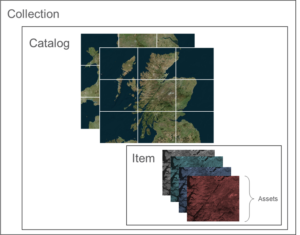
- The STAC Item is the basis of the entire spec. This represents a single ‘thing’ in the STAC catalog and includes its fundamental metadata and the location of the assets, the files that make up the item. This usually might be something like a Landsat scene – a satellite image taken at a place and a moment in time, but with multiple bands, layers and metadata
- The STAC Catalog is the metadata that groups items together. This would be how you’d take all the Landsat scenes and bring them together, .e.g. a catalog of all scenes from Europe between 2017 and 2022
- STAC Collections allow further metadata to be added to the catalog such as data licensing, descriptions and a summary data extent
- The STAC API spec allows you to create a RESTful endpoint to search through all of the above in a faster, programmatic way (if you don’t fancy trawling through JSON). And for the OGC fans, this API aligns with the WFS 3 (Web Feature Service) spec.
STAC has tended to focus on the cataloguing of raster assets, most often earth observation data, but it can be used to catalog any data which represents something captured at a discrete time and in a specific location. Point clouds, land cover data, population maps are all ideal. Vector data may be less suited though – a countrywide dataset of road polygons doesn’t quite fit the brief of discrete time and location, so would be better exposed via a WFS API.
So – what does this all mean in practise?
There are multiple places to start in terms of building your STAC application. stac-server and stac-fastapi can provide a STAC compliant API, based on Elasticsearch and PostgreSQL respectively. With these fast, scalable APIs, users can then point tools like stac-browser towards the API. This excellent open-source web app allows you to create a fully-fledged browser for your STAC assets, and is absurdly lightweight and simple to deploy.
For data scientists, there’s a suite of tools that allows to be accessed from a Python environment, such as PySTAC. For an operation such as creating a cloud free median, this is as simple as querying the catalog for assets which intersect a specific bounding box, with a defined percentage of cloud cover.
For more interactive applications, tools like TiTiler allow fully fledged tile services to stream Cloud Optimised GeoTiff data via an OGC WMTS to web or desktop GIS users. No need for special tile caches, tile servers and special data preparation.
The suite of tools available to plug into STAC, even so early in its life, demonstrates the inherent flexibility of the STAC architecture. Rather than data scientists, GIS analysts and web app users having to be each addressed by separate systems and datasets, with separate design considerations, all three user groups (and more) can be served by a single repository of data. This is especially useful when considering the vast data volumes associated with EO repositories.
The extent to which the architecture can be scaled is demonstrated excellently by Microsoft Planetary Computer and the NASA SmallSat Data Explorer. Both offer up catalogues of rich, high-resolution data accessible for processing, but also make the data easily browsable through a slick portal.

To plug into this rapidly growing STAC ecosystem, Satellite Applications Catapult worked with SpatialDays to create a new tool to support our geospatial intelligence team. The biggest hurdle in creating a rich catalog of data began with the data itself. We were interested in tackling two key issues in our development sprint – how do we enable both our data scientists as well as our non-developer GIS analysts:
- Curate a catalogue of usable data from open access sources
- Store and manage the varied commercial data procured in our project work
One of the most useful trends in EO data science recently has been the cataloguing of large repositories of open data such as Landsat, Sentinel, MODIS and more by organisations such as AWS and Microsoft. These datasets are hugely valuable, and the ease of access afforded by STAC means the effort involved in data preparation can be greatly reduced.
However, much variety can exist between these datasets. Different processing approaches could have been used or perhaps the data could be presented in JPEG2000 or some version of Cloud Optimised GeoTIFF. There are still some considerations to be made on the physical location of data, even when using the cloud. It’s generally better to use data that is in the ‘same cloud’ as your compute, ideally in the same cloud region – especially when some providers may add data egress charges on top of data which would otherwise be free.
To address this, the STAC Portal allows a user to browse various public STAC catalogues, filter by bounding box & data, and pull down a selection of the metadata to load into a ‘local’ server. This means users can curate data for their needs, but with only the metadata being moved, the process is quick and easy. After loading, catalogues can be refreshed at any time, to take in new imagery, or deleted if no longer needed.

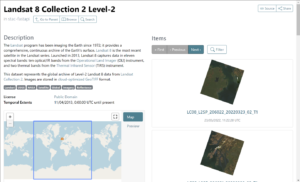
For commercial data, the landscape is far more varied. Virtually every commercial data provider will deliver data from their own portal or platform with different metadata and different packaging. Whilst there is an interest in the STAC spec from data providers, with some previewing STAC compliant deliveries there is still very little consistency.
In order to begin to standardise our repositories of commercial data, we built STAC Portal with the ability for users to drag and drop folders of data into a web interface which are then uploaded into the cloud. Most importantly though, any attached order metadata is extracted and transformed into a STAC compliant format which aids our data management and governance.

The tool currently works with data from Maxar and Planet, but with an extensible architecture that will allow other (non-STAC) providers to be added easily.

The STAC portal is just one small piece of the STAC ecosystem which would not have been possible without other excellent open-source projects already available. This includes stac-fastapi, stac-browser and GDAL. In order to contribute to the ecosystem, we will be making STAC portal available with an open-source licence – making your data management a little simpler in the future.
We welcome comments, contributions and bug reports – check the STAC portal out on our Github.
